ملف Robots.txt: تعليمات الفهرسة وأخطاء التحقق وحلولها
ملف Robots.txt هو ملف نصي يحتوي على تعليمات (توجيهات) لفهرسة صفحات الموقع. باستخدام هذا الملف، يمكنك إخبار روبوتات البحث أي الصفحات أو الأقسام في مورد الويب يجب أن يتم الزحف إليها وإدخالها في الفهرس (قاعدة بيانات محرك البحث) وأيها لا يجب.
يتواجد ملف robots.txt في جذر الموقع ويمكن الوصول إليه عبر domain.com/robots.txt.
لماذا ملف robots.txt ضروري لتحسين محركات البحث (SEO)؟
يقدم هذا الملف تعليمات أساسية لمحركات البحث تؤثر مباشرة على فعالية ترتيب الموقع في محرك البحث. يمكن أن يساعد استخدام robots.txt في:
- منع فحص المحتوى المكرر أو الصفحات غير المفيدة للمستخدمين (مثل نتائج البحث الداخلية، الصفحات التقنية، إلخ) بواسطة زواحف محركات البحث.
- الحفاظ على سرية أقسام الموقع (على سبيل المثال، يمكنك حجب معلومات النظام في نظام إدارة المحتوى من الوصول إليها).
- تجنب تحميل زائد على الخادم.
- استخدام ميزانية الزحف الخاصة بك بفعالية على صفحات ذات قيمة.
من ناحية أخرى، إذا احتوى ملف robots.txt على أخطاء، فستقوم محركات البحث بفهرسة الموقع بشكل خاطئ، وستشمل نتائج البحث معلومات غير صحيحة.
يمكنك أيضًا أن تمنع عن غير قصد فهرسة صفحات مفيدة ضرورية لترتيب موقعك في محركات البحث.
فيما يلي روابط لتعليمات حول كيفية استخدام ملف robots.txt من Google.
محتوى تقرير "أخطاء Robots.txt" على Labrika
هذا ما ستجده في تقريرنا "أخطاء robots.txt":
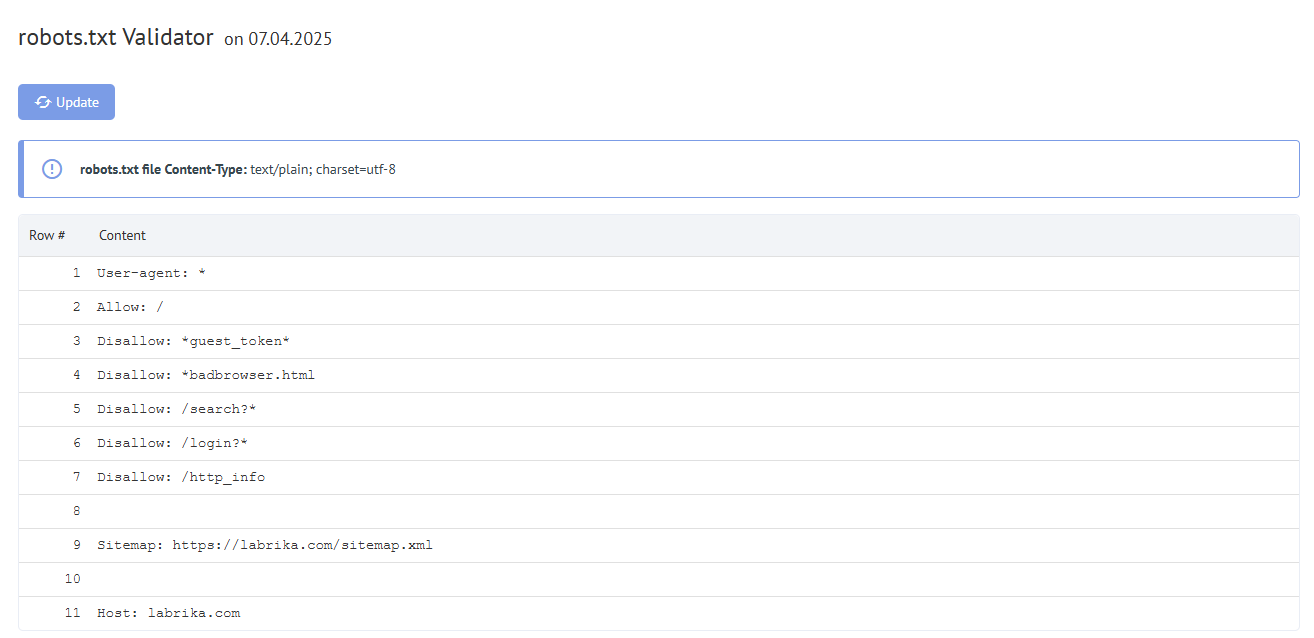
- زر "تحديث" - عند النقر عليه، سيتم تحديث بيانات الأخطاء في ملف robots.txt.
- محتوى ملف robots.txt.
- إذا تم العثور على خطأ، يعرض Labrika وصف الخطأ.
الأخطاء التي يكشفها Labrika في ملف Robots.txt
تجد الأداة الأنواع التالية من الأخطاء:
يجب أن تفصل التوجيه عن القاعدة بواسطة الرمز ":"
يجب أن يحتوي كل سطر صالح في ملف robots.txt على اسم الحقل، نقطتين رأسيتين، والقيمة. الفراغات اختيارية لكنها موصى بها للقراءة. يستخدم رمز الهاش "#" لإضافة تعليق، يوضع قبله. سيتجاهل روبوت محرك البحث كل النص بعد الرمز "#" وحتى نهاية السطر.
الصيغة القياسية:
<field>:<value><#optional-comment>
مثال على خطأ:
User-agent Googlebot
حرف ":" مفقود.
الخيار الصحيح:
User-agent: Googlebot
توجيه فارغ وقاعدة فارغة
استخدام سلسلة فارغة في توجيه user-agent غير مسموح.
هذا هو التوجيه الأساسي الذي يشير إلى نوع روبوت البحث الذي تُكتب له قواعد الفهرسة التالية.
مثال على خطأ:
User-agent:
لم يتم تحديد user-agent.
الخيار الصحيح:
User-agent: اسم الروبوت
على سبيل المثال:
User-agent: Googlebot User-agent: *
يجب أن تحتوي كل قاعدة على توجيه واحد على الأقل من "Allow" أو "Disallow". "Disallow" تغلق قسمًا أو صفحة من الفهرسة. "Allow" كما يشير اسمه يسمح بفهرسة الصفحات. على سبيل المثال، يسمح للزاحف بالزحف إلى مجلد فرعي أو صفحة ضمن مجلد محجوب عادةً من المعالجة.
تُحدد هذه التوجيهات بالشكل:
directive: [path]، حيث [path] (مسار الصفحة أو القسم) اختياري.
مع ذلك، يتجاهل الروبوت توجيهات Allow و Disallow إذا لم تحدد مسارًا. في هذه الحالة، يمكنه فحص كل المحتوى.
توجيه فارغ Disallow: يعادل التوجيه Allow: /، أي "لا تمنع شيئًا".
مثال على خطأ في توجيه Sitemap:
Sitemap:
لم يتم تحديد مسار خريطة الموقع.
الخيار الصحيح:
Sitemap: https://www.site.com/sitemap.xml
لا يوجد توجيه User-agent قبل القاعدة
يجب أن تأتي القاعدة دائمًا بعد توجيه User-agent. وضع قاعدة قبل اسم أول وكيل مستخدم يعني أن لا زواحف ستتبعها.
مثال على خطأ:
Disallow: /category User-agent: Googlebot
الخيار الصحيح:
User-agent: Googlebot Disallow: /category
استخدام صيغة "User-agent: *"
عندما نرى User-agent: * فهذا يعني أن القاعدة موجهة لكل روبوتات البحث.
على سبيل المثال:
User-agent: * Disallow: /
هذا يمنع جميع روبوتات البحث من فهرسة الموقع بأكمله.
يجب أن يكون هناك توجيه User-agent واحد فقط لكل روبوت وتوجيه واحد فقط من User-agent: * لجميع الروبوتات.
إذا كان نفس وكيل المستخدم يحتوي على قوائم قواعد مختلفة محددة في ملف robots.txt عدة مرات، سيكون من الصعب على روبوتات البحث تحديد أي القواعد يجب اتباعها. ونتيجة لذلك، لن يعرف الروبوت القاعدة التي يتبعها.
مثال على خطأ:
User-agent: * Disallow: /category User-agent: * Disallow: /*.pdf
الخيار الصحيح:
User-agent: * Disallow: /category Disallow: /*.pdf
توجيه غير معروف
تم العثور على توجيه غير مدعوم من محرك البحث.
الأسباب قد تكون:
- تم كتابة توجيه غير موجود.
- أخطاء في الصياغة، استخدام رموز وعلامات ممنوعة.
- هذا التوجيه قد يستخدمه روبوتات محركات بحث أخرى.
مثال على خطأ:
Disalow: /catalog
توجيه "Disalow" غير موجود. كان هناك خطأ إملائي في الكلمة.
الخيار الصحيح:
Disallow: /catalog
عدد القواعد في ملف robots.txt يتجاوز الحد الأقصى المسموح
ستعالج روبوتات البحث ملف robots.txt بشكل صحيح إذا لم يتجاوز حجمه 500 كيلوبايت. عدد القواعد المسموح به في الملف هو 2048. المحتوى الذي يتجاوز هذا الحد يتم تجاهله. لتجنب التجاوز، استخدم توجيهات عامة بدلاً من استبعاد كل صفحة على حدة.
على سبيل المثال، إذا كنت بحاجة لحظر فحص ملفات PDF، لا تحظر كل ملف بمفرده. بدلاً من ذلك، امنع كل الروابط التي تحتوي على .pdf بالتوجيه:
Disallow: /*.pdf
القاعدة تتجاوز الطول المسموح به
يجب ألا تزيد القاعدة عن 1024 حرفًا.
صيغة قاعدة غير صحيحة
يجب أن يكون ملف robots.txt مشفرًا بترميز UTF-8 كنص عادي. يمكن لمحركات البحث تجاهل الأحرف غير المشفرة بـ UTF-8. في هذه الحالة، لن تعمل القواعد من ملف robots.txt.
لكي تعالج روبوتات البحث التعليمات بشكل صحيح في ملف robots.txt، يجب كتابة كل القواعد وفقًا لمعيار استبعاد الروبوتات (REP)، الذي تدعمه Google ومعظم محركات البحث المعروفة.
استخدام الأحرف الوطنية
استخدام الأحرف الوطنية محظور في ملف robots.txt. وفقًا لنظام أسماء النطاقات المعتمد، يمكن أن يتكون اسم النطاق فقط من مجموعة محدودة من أحرف ASCII (حروف الأبجدية اللاتينية، أرقام من 0 إلى 9، وشرطة). إذا احتوى النطاق على أحرف غير ASCII (بما في ذلك الأبجديات الوطنية)، يجب تحويله إلى Punycode إلى مجموعة أحرف صالحة.
مثال على خطأ:
User-agent: Googlebot Sitemap: https: //bücher.tld/sitemap.xml
الخيار الصحيح:
User-agent: Googlebot Sitemap: https://xn-bcher-kva.tld/sitemap.xml
قد تم استخدام حرف غير صالح
مسموح باستخدام الأحرف الخاصة "*" و "$". تحدد أنماط العناوين عند إعلان التوجيهات حتى لا يضطر المستخدم إلى كتابة قائمة طويلة من عناوين URL النهائية للحظر.
على سبيل المثال:
Disallow: /*.php$