ما هو الفهرسة؟
الفهرسة هي عملية تحليل صفحات الموقع (يتم ذلك عادةً بواسطة محركات البحث) ثم بعد الزحف، إضافتها إلى فهارس محركات البحث. يتم استخدام هذا الفهرس (قاعدة البيانات) لتشكيل نتائج البحث، وأيضًا ترتيب الصفحات داخل نتائج البحث (بعد أن تحلل الخوارزميات الصفحات بناءً على رضا نية الاستعلام ونجاح تحسين محركات البحث). يتم إجراء الفهرسة بواسطة زاحف/روبوت محرك البحث.
لماذا نحتاج إلى القدرة على استبعاد المعلومات من فهارس محركات البحث؟
كقاعدة عامة، يمكن حظر المعلومات التي يجب عدم عرضها في نتائج البحث من فهارس محركات البحث باستخدام علامة “noindex” أو بحظر الزحف على أقسام/صفحات معينة من الموقع ضمن ملف robots.txt.
الصفحات التي يتم حظرها عادةً من محركات البحث هي من طبيعة فنية، ملكية، وسرية، وتُعتبر غير مناسبة للوضع في نتائج البحث.
أمثلة على ذلك داخل موقع تجاري قد تكون روابط تشير إلى؛ حسابات المستخدمين، عربات التسوق، مقارنات المنتجات، الصفحات المكررة، نتائج البحث داخل الموقع وهكذا!
هذه الصفحات قيمة للعملاء وأساسية لوظائف الموقع، لكنها غير مفيدة لفهارس محركات البحث.
طرق حظر الصفحات من الفهرسة بواسطة محركات البحث
هناك العديد من الطرق لمنع فهرسة الصفحات:
-
استخدام ملف robots.txt.
Robots.txt هو ملف نصي يخبر محركات البحث الصفحات التي يمكنه فهرستها والصفحات التي لا يمكنه فهرستها.
لحظر صفحة من الفهرسة في robots.txt، يجب استخدام توجيه Disallow.
مثال على ملف robots.txt يسمح بفهرسة صفحات الكتالوج بينما يمنع فهرسة العربة:
# محتوى ملف robots.txt، # والذي يجب أن يكون في الدليل الجذر للموقع # تمكين فهرسة الصفحات والملفات التي تبدأ بـ '/catalog' Allow: /catalog # حظر فهرسة الصفحات والملفات التي تبدأ بـ '/cart' Disallow: /cart
-
استخدام علامة <meta> robots مع السمة noindex.
لحظر صفحة باستخدام هذه السمة، تحتاج إلى إضافة الأسطر التالية إلى قسم
<head>للصفحة:لحظر الصفحة بأكملها من الفهرسة يجب وضع السطر التالي في كتلة
<head>للصفحة نفسها:<meta name="robots" content="noindex">
-
عدم اتباع الروابط بحيث لا تفهرس الصفحة التي تشير إليها.
هناك طريقتان للقيام بذلك:
-
حظر الزاحف من اتباع رابط على أساس رابط برابط:
<a href="/page" rel="nofollow"> نص الرابط </a>
تذكر أن هذه الطريقة ستعمل فقط إذا كان كل رابط واحد إلى الصفحة يحتوي على السمة “nofollow” فيه. إذا كان رابط واحد يفتقر إلى هذه السمة، فسيتبع زاحف محرك البحث ذلك وسيتم فهرسة الصفحة.
-
حظر الزاحف من اتباع أي رابط على الصفحة بإعطاء الصفحة نفسها السمة nofollow:
بإضافة السطر أدناه إلى كتلة
<head>على الصفحة، سيتم حظر الزاحف من اتباع الصفحة وبالتالي لن يتم فهرسة أي روابط موجودة داخل الصفحة.<meta name="robots" content="nofollow" />
-
-
يمكنك أيضًا حظر الصفحة من الزحف بواسطة أي محرك بحث محدد في رأس صفحة HTML، على سبيل المثال:
يمكنك وضع هذا السطر في كتلة
<head>على الصفحة نفسها؛ سيحظر هذا الصفحة من الفهرسة بواسطة Google (حيث حظرت زاحفهم تمامًا):<meta name="googlebot" content="noindex">
يمكنك أيضًا اختيار “noindex” صفحة محددة بينما تسمح لـ Google باتباع الروابط على الصفحة المذكورة، ثم فهرسة الصفحات المرتبطة من الصفحة “noindex”:
<meta name="googlebot" content="noindex, follow">
-
الصفحة الأساسية.
يُستخدم السمة rel=canonical للإشارة إلى محرك البحث أن الصفحة هي صفحة أساسية (الأكثر سلطة). يشير هذا إلى الزاحف أن هذه هي الصفحة المفضلة للفهرسة وهي المثال الأكثر سلطة لهذا المحتوى على موقعهم.
تحديد الصفحات الأساسية ضروري لتجنب فهرسة الصفحات ذات المحتوى المتطابق مما يمكن أن يضر ترتيب الصفحة في SERP.
ستستخدم هذه السمة عندما يكون لديك صفحات متعددة ذات محتوى متطابق لكن عناوين URL مختلفة لأجهزة مختلفة:
https://example.com/news/https://m.example.com/news/https://amp.example.com/news/
أو عندما تكون هناك خيارات ‘ترتيب’ متعددة متاحة للصفحة ستغير عنوان URL للصفحة لكنها تظهر نفس المحتوى:
https://example.com/catalog/https://example.com/catalog?sort=datehttps://example.com/catalog?sort=cost
أو إذا حدد الرابط أحجامًا مختلفة لمنتج معين داخل عنوان URL:
https://example.com/catalog/shirthttps://example.com/catalog/shirt?size=XLhttps://example.com/catalog/shirt38
يتم تطبيق السمة rel=canonical كالتالي:
<link rel=canonical href="https://example.com/catalog/shirt" />
ملاحظة: يجب وضع هذه السمة في كتلة
<head>للصفحةمن الممكن أيضًا إدخال الصفحة الأساسية المرغوبة في رأس طلب HTTP.
ومع ذلك، كن حذرًا لأنه بدون استخدام ملحقات خاصة لمتصفحك، لن تتمكن من التحقق مما إذا تم تعيين هذه السمة بشكل صحيح حيث لا تعرض معظم المتصفحات رؤوس HTTP لمستخدميها.
HTTP / 1.1 200 OK Link: <https://example.com/catalog/shirt>; rel=canonical
يمكنك قراءة المزيد عن الصفحات الأساسية في وثائق Google.
-
استخدام رأس طلب HTTP "X-Robots-Tag" لعنوان URL محدد:
HTTP / 1.1 200 OK X-Robots-Tag: google: noindex
كن حذرًا لأنه بدون استخدام ملحقات خاصة لمتصفحك، لن تتمكن من التحقق مما إذا تم تعيين هذه السمة بشكل صحيح حيث لا تعرض معظم المتصفحات رؤوس HTTP لمستخدميها.
كيف أجد الصفحات التي تم حظرها من الفهرسة على موقعي؟
يمكنك عرض هذه المعلومات في قسم "تدقيق SEO" - "الصفحات المحظورة من الفهرسة" في لوحة تحكم Labrika الخاصة بك.
في صفحة التقرير يمكنك تصفية النتائج لرؤية أي صفحات هبوط تم حظرها من الفهرسة. للقيام بذلك تحتاج إلى النقر على زر “خطأ حرج”.
عادةً، عندما يزور زاحف محرك البحث موقعك، سيزحف جميع الصفحات التي يمكنه العثور عليها عبر الروابط الداخلية ثم يفهرسها وفقًا لذلك.
الهدف من هذا التقرير هو إظهار أي صفحات تم حظرها من الفهرسة. هذه تميل إلى أن تكون صفحات لا تحتوي على كلمات مفتاحية في أفضل 50 نتيجة بحث، وقد تم حظرها عمدًا من الفهرسة بواسطة محركات البحث من قبلك.
تقرير “الصفحات المحظورة من الفهرسة” لـ Labrika
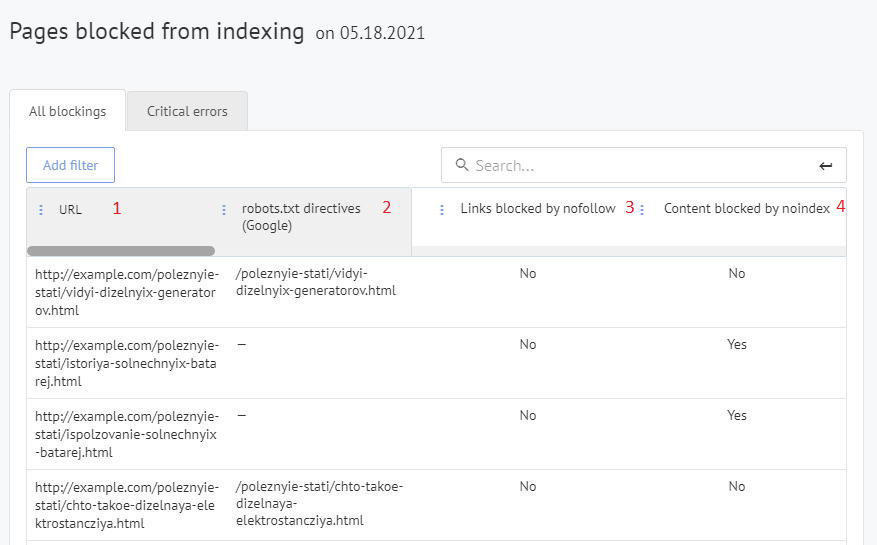
- عنوان URL لأي صفحات محظورة من الفهرسة حاليًا.
- التوجيه في robots.txt الذي يحظر الفهرسة لهذه الصفحة (إذا تم حظر الصفحة من الفهرسة في Google بهذه الطريقة).
- ما إذا كانت هذه الصفحة محظورة عبر السمة nofollow.
كيف أوقف صفحة من أن تكون noindexed موجودة داخل هذا التقرير؟
في العديد من أنظمة إدارة المحتوى الحديثة (CMS)، يمكنك تغيير ملف robots.txt، rel= canonical، علامة meta "robots"، “noindex”، وسمات “nofollow”. لذلك، لجعل صفحة قابلة للفهرسة مرة أخرى موجودة داخل هذا التقرير، ستحتاج فقط إلى إزالة السمة/العلامة التي تسبب عدم فهرسة هذه الصفحة. هناك العديد من الملحقات البسيطة التي تسمح لك بالقيام بذلك. إذا لم تتمكن من تغييره بنفسك فسيكون مهمة بسيطة نسبيًا لتفويضها إلى مطور.